Dear Colleagues and Leaders in Oncology,
We write to you today as scientists, innovators, and founders committed to transforming how humanity understands, detects, and ultimately defeats cancer. We are Dr. Mones Abu-Asab and Mohamed Chaouchi, co-founders of Phyloncology, and we extend to you an open invitation—whether through collaboration, strategic partnership, or even acquisition—to explore a breakthrough approach that redefines cancer diagnostics.
Why Phyloncology Exists
After decades of research—spanning evolutionary biology, pathology, data science, and clinical studies—we reached a simple but profound conclusion: cancer cannot be solved by viewing it through the wrong analytical lens.
The oncology community has long been anchored to a mutation-centric view of cancer. From our work at the George Washington University School of Medicine and the NIH and through the engineering and computational frameworks we developed together, we have demonstrated that cancer is fundamentally an evolutionary imbalance rooted in cellular energy disruption.
This recognition led us to build Phyloncology, and with it, a phylogenetics-based diagnostic platform that treats cancer as what it truly is: an evolving system.
What We Bring to the Table
1. A Universal, Non-Biomarker-Dependent Diagnostic Method
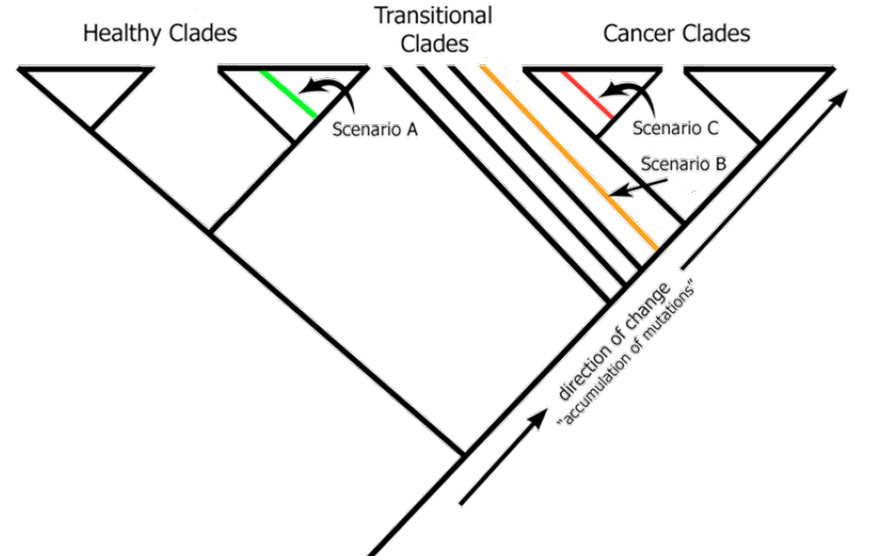
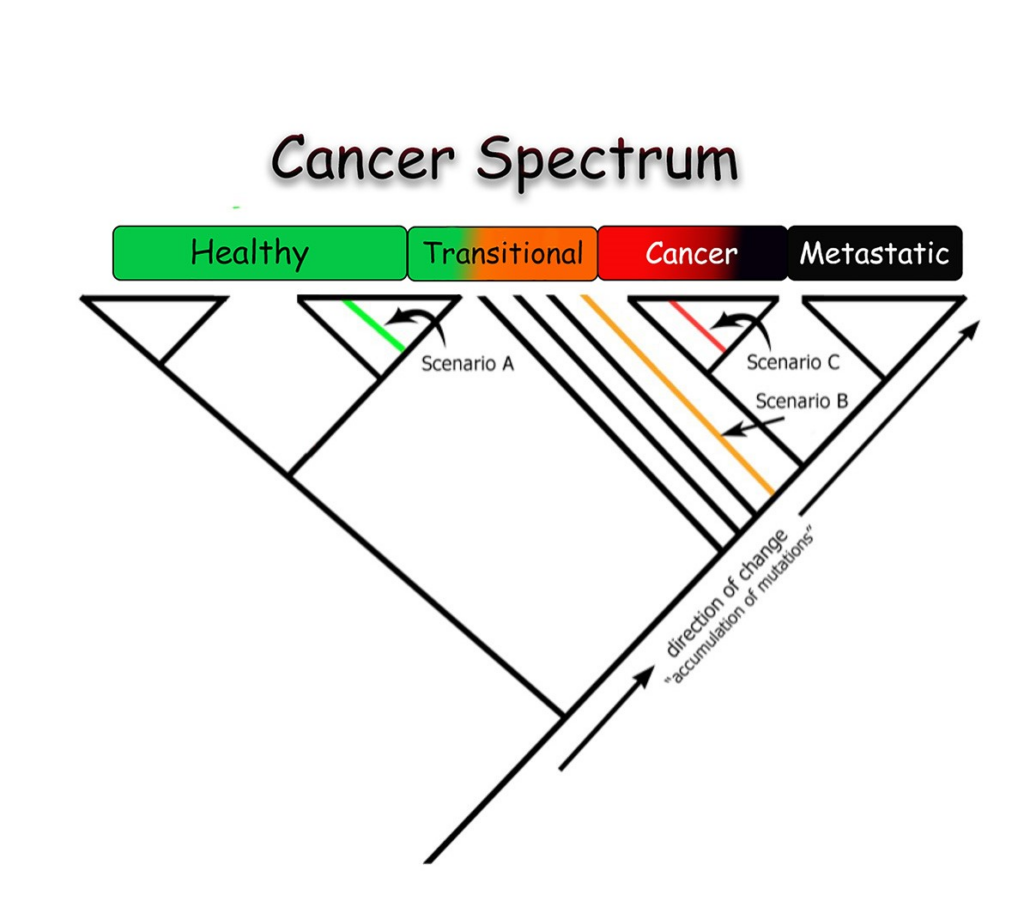
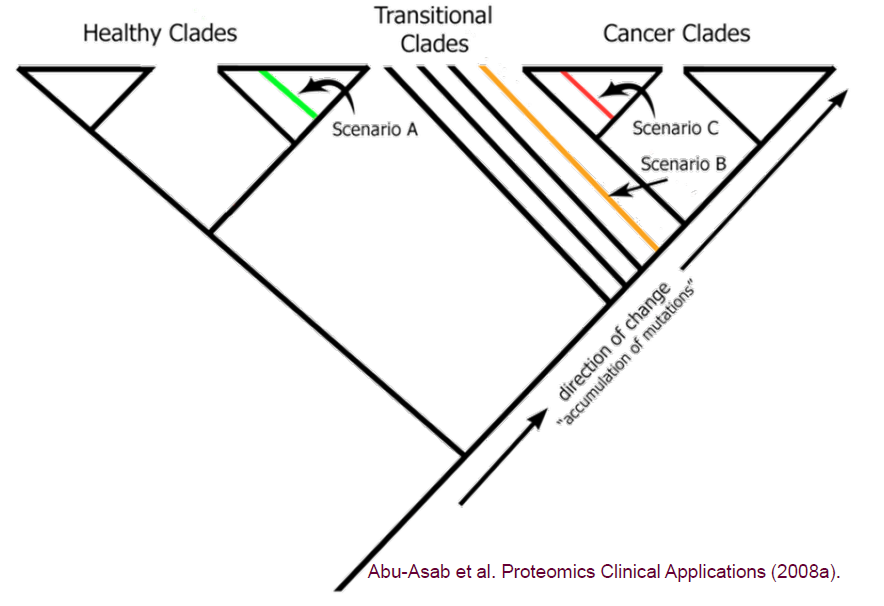
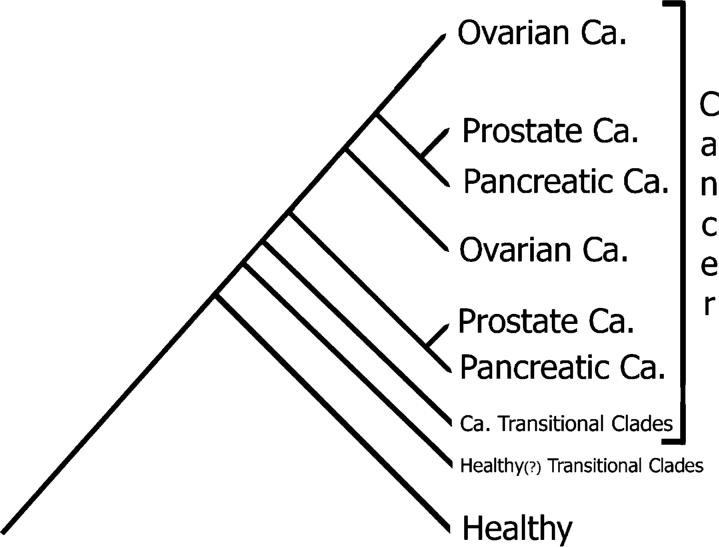
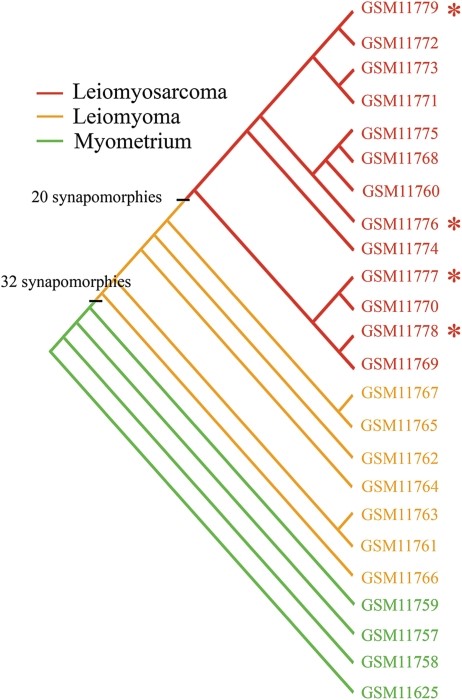
Our technology does not rely on fragile, cancer-specific biomarkers. Instead, we use cladistics and phylogenetic analysis—the gold standard in evolutionary biology—to classify samples into healthy, transitional, or cancerous states.
This methodology is:
- Applicable across all cancer types
- Able to use any high-dimensional data (metabolomics, proteomics, gene expression)
- Resistant to cancer heterogeneity, which other analytical approaches treat as noise
2. Patented and Validated Technology
Our algorithm, conceived in 2005, patented in 2014, and refined through years of interdisciplinary development, preserves the full richness of biological data—without forcing statistical oversimplification.
3. Compelling Clinical Performance
Across multiple studies, our platform has shown exceptional promise:
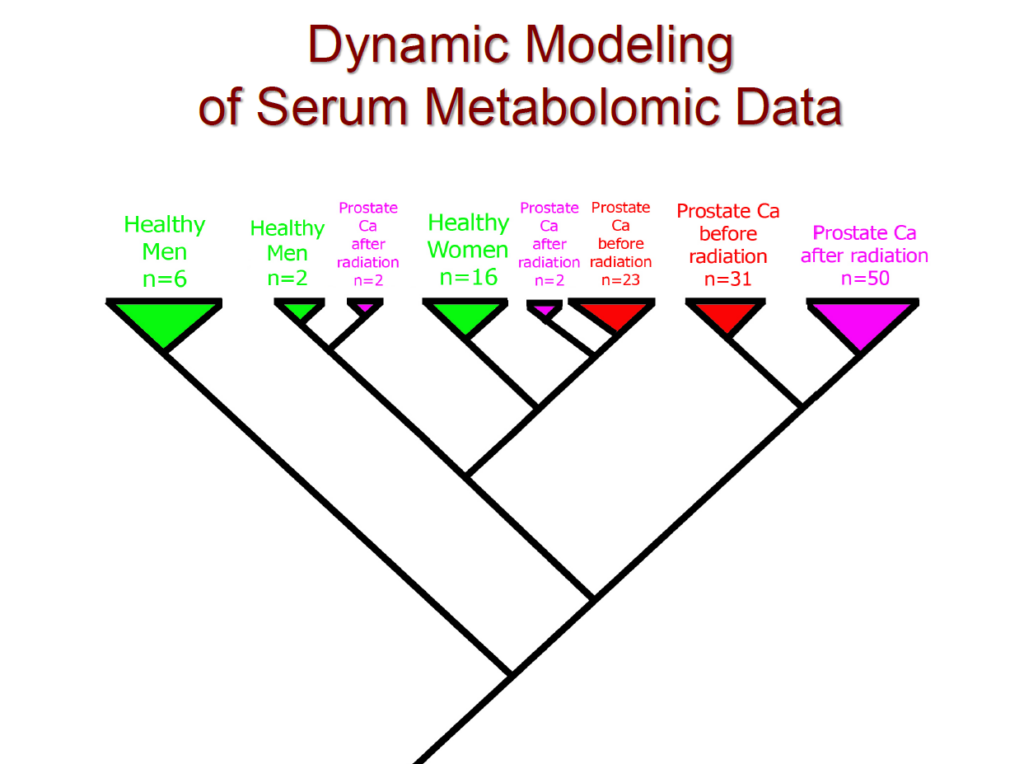
- 100% separation of healthy vs. cancer patients in a prostate-cancer cohort using serum metabolomics
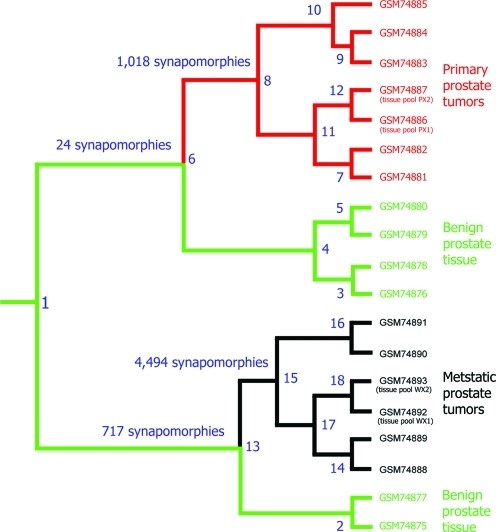
- Distinction between primary and metastatic tumors using gene-expression data
- Clear classification of male vs. female physiological signatures using serum data
These results validate a core principle: evolution tells the truth that statistics often hides.
4. Cost-Effective, Scalable, and Clinically Friendly
- Non-invasive: a simple blood draw
- Standard mass-spectrometry processing (~$100 per sample)
- Upload via web interface to generate real-time classification against a robust “master cladogram”
Once built, each cancer-type cladogram supports continuous, global deployment.
5. Clear, Realistic Deployment Paths
We have mapped out two viable strategies:
- Regulatory Route:
Approximately $1M needed for FDA approval of our first indication. - Market Adoption Route:
Begin by building reference cohorts (500–1,000 samples per cancer type), integrate with labs, hospitals, and insurers, and scale diagnostics through a cloud-native platform.
Why the Oncology World Should Pay Attention
Despite remarkable technological advances, early cancer detection remains constrained by a biomarker-first mindset and analytical tools that aren’t built to handle evolutionary heterogeneity.
Phyloncology offers a new paradigm—one that uses heterogeneity as signal, not noise.
Our approach is not another dataset, biomarker, or statistical model. It is a fundamentally different analytical framework that reflects the biological reality of cancer.
An Open Invitation: Let’s Build the Future of Cancer Diagnostics Together
We believe Phyloncology has the potential to become a cornerstone technology for early detection. But to accelerate its impact, we welcome:
- Collaborations on pilot clinical studies
- Licensing or co-development partnerships
- Strategic acquisition discussions for organizations seeking a universal diagnostic engine
- Joint regulatory or commercialization pathways
You bring global reach, infrastructure, and clinical scale.
We bring a validated, patented, evolutionary platform with the potential to redefine detection.
Together, we can act faster—and save lives sooner.
Why Now
We are a small, focused team with a large vision. We have self-funded, avoided unnecessary dilution, and developed a platform built on decades of scientific rigor and engineering discipline.
But scaling a paradigm shift requires partners with the reach and resources to match the urgency of the mission.
Cancer won’t wait. Patients won’t wait. Neither should we.
A Call to Action
We invite you—the leaders shaping the future of oncology—to:
- Review our work and scientific foundations
- Engage with us in conversation
- Explore a pilot, partnership, or strategic alignment
If you are ready to embrace a truly evolutionary approach to cancer, we’re ready to collaborate.
Thank you for your time, your leadership, and your commitment to creating a future where early detection is accurate, universal, and accessible.
With deep respect and determination,
Mones Abu-Asab, PhD
Mohamed Chaouchi
Co-Founders, Phyloncology LLC